Friday, September 19th, 2025
Compliance Without Compromise: How Harbor Ships Fast and Stays Constantly Validated
With traditional electronic data capture (EDC) vendors, a validation cycle means waiting months for new features, and hoping nothing slipped through the cracks. With Harbor, every release is validated to meet regulatory standards automatically. That means you get faster product improvements, and when auditors show up, you already have a full validation package ready to go.

Overview
Harbor EDC is used by medical device and pharmaceutical companies to collect, store, and visualize data from clinical studies. While EDCs have been around since the 1980s, today's systems feel like their usability and features froze sometime around 2000. In my past experiences working on clinical trials, today's EDCs are not only clunky, but also slow and unreliable. Entering data is a laborious, error-prone process and keeping track of study progress requires a messy collection of custom spreadsheets and scripts built outside of the EDC.
For too long, "It's regulated enterprise software" has been used as a justification for slow performance, poor user experience, and lack of customization. We believe that the people running clinical trials deserve better tools. With Harbor, we wanted to build a modern software experience while still meeting the strict, regulatory and security requirements necessary for clinical trials.1
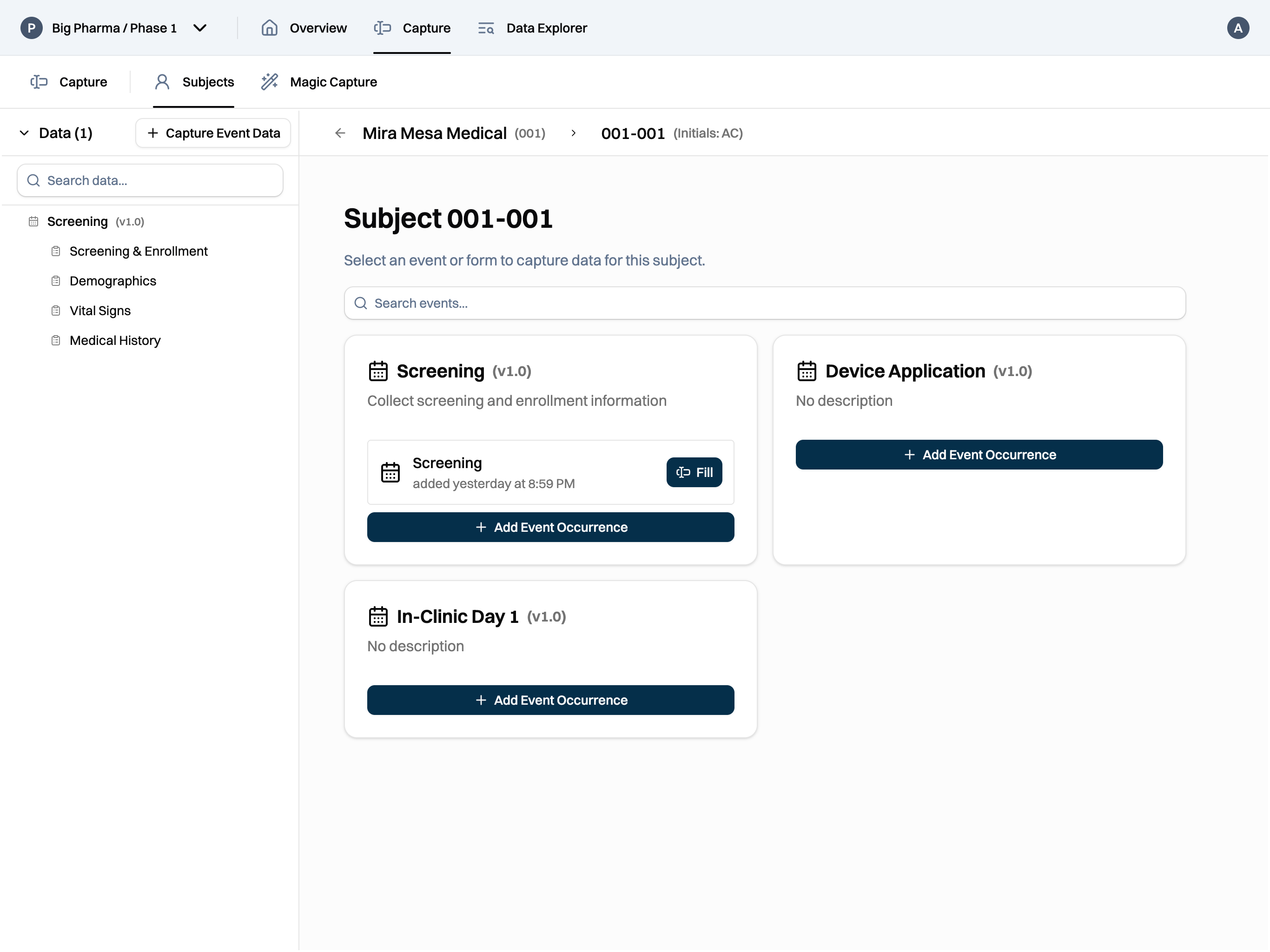
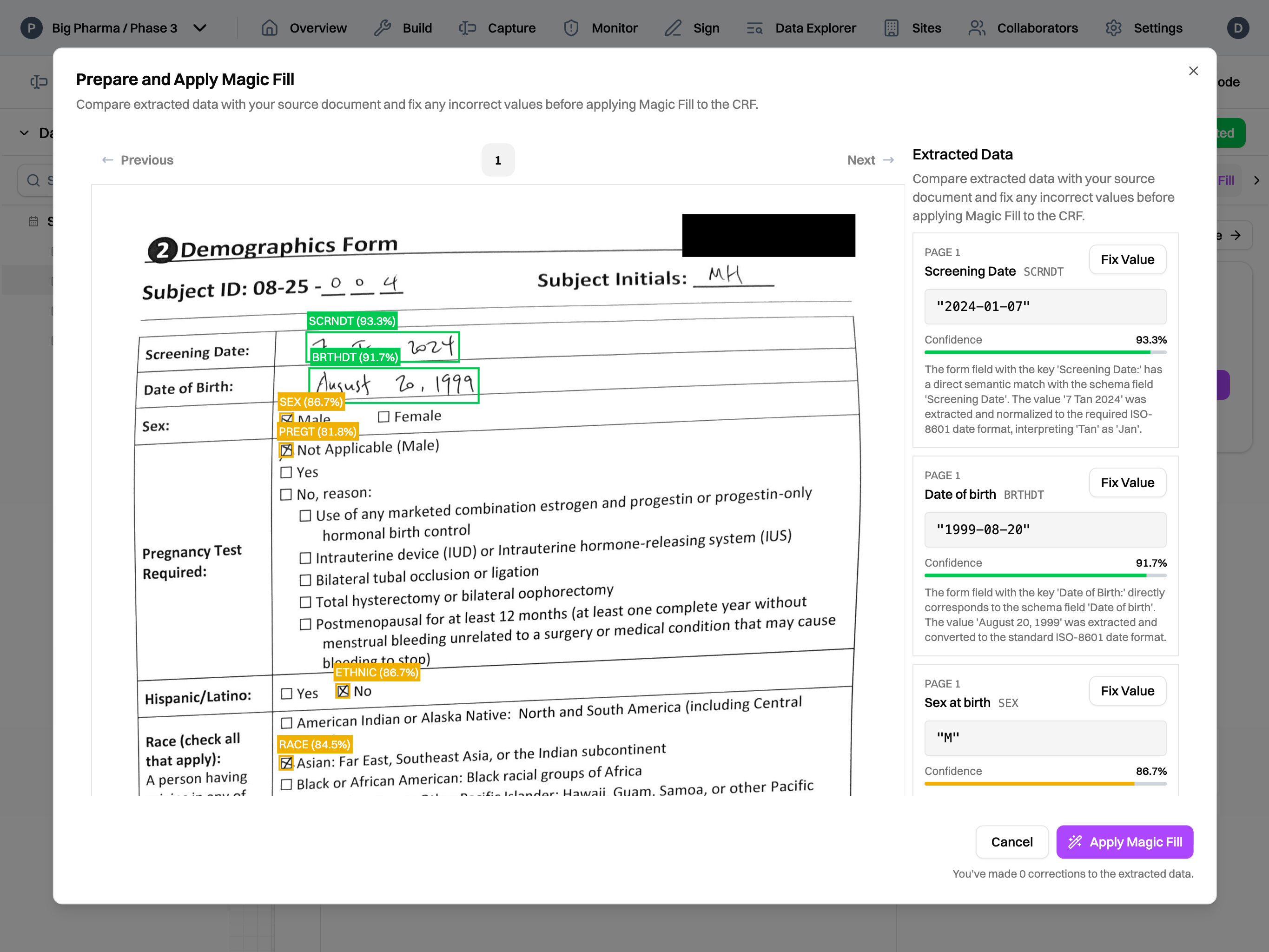
At traditional EDC companies, the "V-model" for software development and manual validation documentation were the state of the art when their products were built. But, software engineering has evolved while validation practices haven't. Especially in an industry like clinical trials, we did not want to rely on a manually maintained web of Word documents and spreadsheets where a single copy-paste error or a missed row in a traceability matrix can have serious consequences.
As a result, we decided to take a fresh approach to the software development and validation process when we built Harbor EDC. What we realized is that regulations don't have to prevent great software from being built in clinical trials. In fact, with the right tooling and approach to software development, we found that it's possible to be fully compliant, constantly validated, and fast-moving.
To do this, we take advantage of modern software development methodologies pioneered by companies like Google, (where my co-founder previously worked as a software engineer). These methodologies, like continuous integration and automated testing, are now standard in every other mission-critical industry, from banking to aerospace. At Harbor, we're simply adapting those techniques for clinical trials. The result is more rigorous testing, more reliable software, and faster iteration.
| The Traditional Approach | The Harbor Approach | |
|---|---|---|
| Requirements | Are stored in separate Word docs or spreadsheets. | Live right next to the application code. |
| Traceability | Manual, error-prone process of linking requirements to tests in a separate traceability matrix. | Automatically generated and enforced with deployment prevented if any requirement is untraced. |
| Validation State | Validated only at the moment of release and new work can move it out of a validated state. | Constantly validated. Every change is automatically checked against all requirements before deployment. |
| Documentation | A validation package is manually assembled. | Human-readable documents (requirements, traceability matrix, test reports) are automatically generated. |
| Release Cycle | Slow and infrequent. New features are batched into major releases every few months to accommodate the long validation cycle. | Fast and iterative. New features and improvements can be released as soon as they are ready, without compromising compliance. |
| Risk of Error | High. Relies on human vigilance to prevent mistakes like copy-paste errors or missed traceability links. | Low. The process is automated and enforced by the system, significantly reducing the risk of human error. |
What are the actual regulations?
EDCs, and clinical trial software generally, sit in a gray zone in official regulations and guidances. Let's say a medical device company (the "Sponsor") is looking to run a clinical trial. By the letter of the law, the Sponsor, not the EDC software vendor, is ultimately responsible for the quality of the data collected in the trial. In theory, this means that a software vendor does not actually need to perform software validation before selling to Sponsor customers. Of course, in practice, this never happens. If a Sponsor were to collect their clinical trial data using an unvalidated EDC system, the data would not be usable for any sort of regulatory submission.2,3
The relevant guidelines are:
- ICH E6 R3 (more commonly referred to as "Good Clinical Practice" or "GCP")
- 21 CFR Part 820 (Quality system regulation)
- 21 CFR Part 11 (Electronic records and signatures)
- 21 CFR Part 812 (Investigational device exemptions); and
- A number of FDA guidances, including "Electronic Systems, Electronic Records, and Electronic Signatures in Clinical Investigations: Questions and Answers" and "General Principles of Software Validation"
While the regulations can seem dense and intimidating, their core principles are quite sensible for protection of subjects and data integrity. In fact, at Harbor, we have long maintained that working in a "regulated software environment" is not very different from standard software development practices; the only difference is that those standard practices must be officially documented in some form. At a high level, the regulations require that the software must have controls in place to ensure that collected data is authentic, complete, and secure. This includes features like secure user access controls, timestamped recordings of all data changes, and protection against data loss. Additionally, the software must have gone through a validation process that demonstrates that the software is able to perform those functions consistently and reliably. These are all reasonable requirements for any sort of high-quality, safety-critical software product, regulated or not.
What goes into software validation?
Software validation, for the purpose of software involved in a regulatory submission, is the process of creating documented evidence that the system performs as intended. Generally, the steps are as follows:
- Software validation plan: To start, the plan should outline the intended use of the software. For Harbor EDC, the intended use is: "The software is used by clinical trial sponsors and site staff for the collection, management, and reporting of clinical trial data intended for regulatory submissions." From there, the software validation plan covers the boundaries of the validation (e.g., the software will be validated but the end user's browser and hardware on which the software runs is out of scope) and defines the overall validation approach. For example, how do you determine the risk levels for each software function? For each risk level, what will be the appropriate testing or mitigation required?
- Defining requirements: This step translates the intended use into specific, testable requirements. We document exactly what the software needs to do from a functional, technical, and user perspective. These requirements form the foundation for the entire validation effort. After all, you can't prove a system works if you haven't defined what "working" means.
- Test protocols: With requirements defined, you must now outline what you expect the software to do and how you’re going to prove it. The test plan documents why and how we’re going to verify the software. Test protocols contain specific, step-by-step instructions designed to re-create common scenarios, uncover potential errors, and demonstrate that key features are performing exactly as required.
- Test execution and reporting: Here, test protocols are executed. The approved test protocols are run, and the results – both expected and actual – are documented. This creates the objective evidence that the software meets its pre-defined requirements.
- Final validation package: After testing is complete, the final validation report is written, reviewed, and approved. This report summarizes the entire effort and provides a final statement on the system's fitness for its intended use. This package also includes all the necessary procedures for the software's ongoing use, covering support, training, security, backup, and recovery plans before the system is officially released.
How is it normally done?
Before we talk about our approach, let's consider how software validation is done at most organizations.
- A software validation plan is written, signed, and released. There's not too much to write home about here.
- Software requirements are drafted. For an organization following the full V-model or "waterfall" approach to validation, requirements are drafted all at once. For an organization following an agile software development approach, requirements might be drafted and adjusted as the software is being developed. Regardless, these requirements are usually in a Word document or spreadsheet, separate from the actual application code.
- Tests might include a variety of unit testing, integration testing, and functional testing. Test protocols are written, often in Word documents or spreadsheets and care must be taken to ensure that every requirement is properly traced and verified by a test. While unit tests and sometimes integration tests are automated, functional testing still relies on a human user to go through and interact with the software to confirm the application is behaving as expected.
- To generate a final validation package, test reports are compiled into a Word document or PDF and signed. This typically involves a tangled web of spreadsheets, PDFs, and Word documents, where maintaining traceability between requirements and their associated tests is a manual effort prone to human error.
How does Harbor do it?
The traditional approach described above works for most situations but relies on a considerable amount of human vigilance to make sure that requirements, tests, and traceability between requirements and tests stay in sync. Especially as new features are added and the software grows in complexity, managing these moving pieces can slow things down significantly, or, even worse, requirements may go untested and move the software out of its validated state. As a result, small, agile EDC vendors might release new features every 2-3 months (e.g., Viedoc), while legacy players move even more slowly (e.g., Oracle).
At Harbor, almost everything we do resides within a single "monorepo." (This even includes the blog post you're reading right now.) This means that the EDC application code and its software validation sit side-by-side in our code repository.
- Software requirements are written in a structured, machine-readable format, specifically YAML. Like most organizations, Harbor's software requirements have a unique requirement ID, short name, description, and rationale. In fact, for organizations who keep their requirements in spreadsheets or tables in Word documents (which is most organizations), the approach is almost identical.
- From requirements, we carefully consider potential risks associated with each requirement. For example, a risk associated with the requirement "Encryption in transit" above would include the failure mode, "Communication occurs over unencrypted HTTP." Each risk is carefully considered for its severity (determined by its potential impact on subject safety, data integrity, and regulatory compliance) and its probability (determined based on the complexity of the function and the novelty of the technology used). These two factors, severity and probability, are used to determine the testing strategy to ensure each risk is appropriately mitigated.
- id: nf-se-001
name: Encryption in transit
type: non-functional
description: >
The system must enforce HTTPS for all client-server communication. The server must be configured to use Transport Layer Security (TLS) version 1.2 or higher and must disable support for all older SSL/TLS versions. The TLS configuration must utilize strong, industry-accepted cipher suites.
rationale: >
This ensures the confidentiality and integrity of sensitive clinical trial data in transit.
So far, none of this is particularly novel. You might think, "Sure, you've written your requirements and risks in YAML instead of tables in a Word document. What's the big deal?"
Because Harbor EDC is a pure software system, every test for our application can be automated. This includes unit tests, integration tests, and even functional tests where we use the Playwright framework to test user interactions. Playwright allows you to script actions like "Click on this button" and "Enter hunter2 in this password input field." By chaining these actions together, we can automate a more complicated workflow like "Attempt to log in to Harbor EDC six times with the incorrect password and check that you are locked out from trying any more times." We can also quickly run our tests across different browsers while sharing the same Playwright testing code.
By combining machine-readable risks and requirements with automated test scripts, we are now able to automate one of the riskiest and most tedious parts of keeping a system validated: maintaining a traceability matrix. Every validation test in the Harbor EDC application is tagged with an annotation for the requirement it verifies or risk that it mitigates (e.g., @verifies{nf-se-001}, @mitigates{ra-se-001}). As a result, a script can be used to generate the traceability matrix. If there are any requirements or risks that go unverified or unmitigated, the traceability matrix generation script will generate an error message noting the unverified requirement(s) and/or unmitigated risk(s) and exit. Because this script is part of Harbor's deployment pipeline, the script failing will prevent the latest code changes from being deployed. This makes it impossible to deploy code to our production server that is not fully validated.
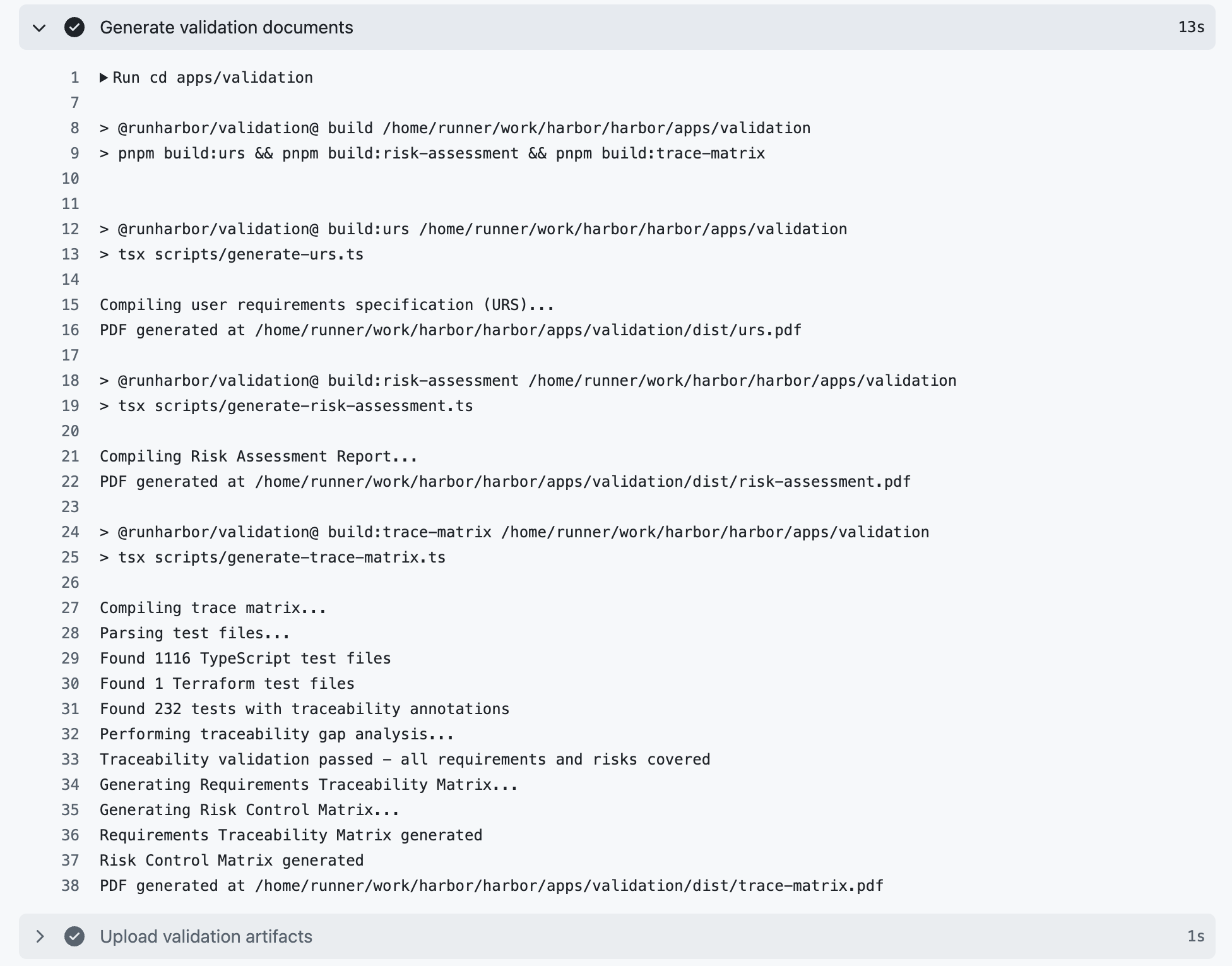
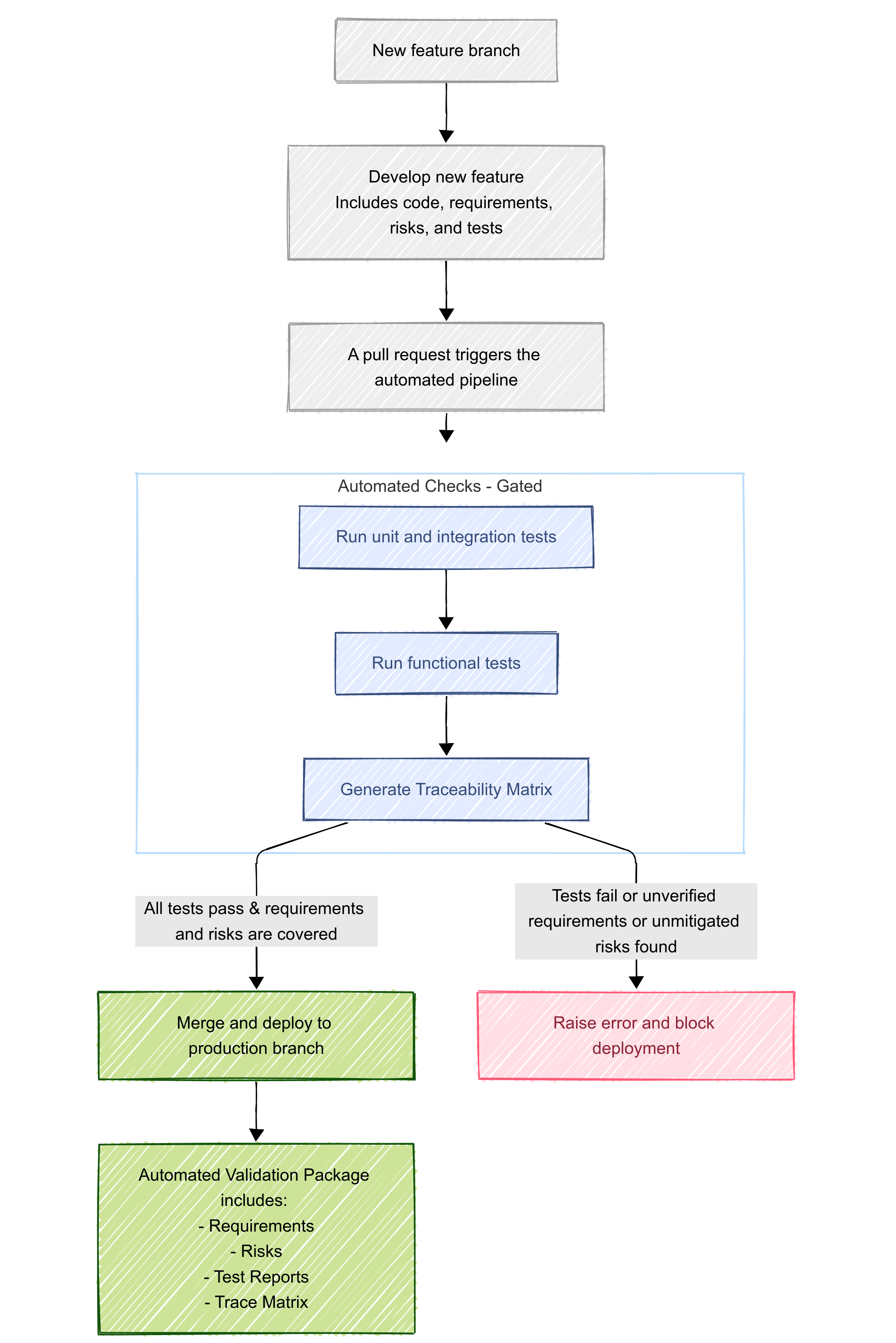
Here's how that works in practice. When a new feature is added, the work is done on a separate branch from production. On that branch, we follow a normal agile approach, creating requirements, developing the feature, assessing and documenting risks, and writing tests all in the same place. Before the feature can be deployed to production, our automated deployment process ensures that all tests pass and all requirements and risks are traced to at least one test before deployment occurs. Additionally, the process takes our machine-readable requirements, risks, and traceability matrix and turns them all into human-friendly PDFs. The release version and commit hash are included in the PDFs automatically. These documents are combined with our standard operational procedures and policies and signed off by our team to constitute our standard "validation package" that is ready to hand off to a customer – or, more likely, a customer's auditor.4
Finally, this approach isn't completely foolproof. Writing accurate requirements, identifying and assessing risks, and developing and annotating tests are all still very "human-in-the-loop" processes where things can go wrong. (There are, of course, companies working on using LLMs for this.) Still, the approach we've developed at Harbor makes sure that our EDC stays constantly validated and that the data it collects stays ready for regulatory submission without slowing our development velocity down. The result is faster feature development and delivery for customers without risking non-compliance.
For sponsors: don't let your EDC's release cycle dictate your study's timeline. Our continuously validated approach means the technology adapts to your trial, not the other way around. If you're interested in how this can de-risk your timeline and simplify your audit preparation, please reach out.
Footnotes
-
Some of this is inspired by tools and apps like Linear, Slack, and Robinhood – products that took domains people expected to be boring or intimidating and made them actually enjoyable. We want to bring the same ethos to clinical trial software. ↩
-
As a sidenote, this does leave an interesting gap for clinical trial data that is not intended for use in a regulatory submission. These studies, especially common in academia where the goal is a publication rather than commercialization, can utilize a cheaper or even self-hosted, open-source option like RedCap that does not come with Part 11 compliance out of the box. This is also why most major research universities' IT departments spin up their individual instances of RedCap that the universities' researchers can use (e.g., University of Michigan, UCLA). This has also led to companies like RedCap Cloud who have taken open-source RedCap and wrapped it into a hosted service with Part 11 compliance so that it can be sold to commercial customers. ↩
-
To make things grayer, even when buying an off-the-shelf "pre-validated" EDC, sponsors are ultimately responsible for the validation of the EDC in the context of their particular clinical trial. As a simple example, as Harbor, we can validate that our software handles the ability to create a "Date" field type in a case report form (CRF) properly. However, it is the sponsor's responsibility to validate that the "Date" field is configured properly within a specific context (e.g., "Date of birth" on a "Demographics" CRF). This is usually done and documented through user acceptance testing (UAT), something that Harbor is also planning to build AI tools to help with by generating realistic, simulated subject data to test the EDC set up before a study goes live. ↩
-
I don't think pull requests within GitHub constitute a Part 11 compliant signature, which is why we still route our final validation package for each release through Adobe Sign. If anyone has come up with a solution for this, let me know. ↩